marcc-hpc.github.io/esc.In a previous section, we explained that Blue Crab is a shared resource accessible only via login nodes. Users connect to the login nodes, prepare their calculations, and submit batch jobs to a scheduler.
That scheduler is called SLURM, the simple linux utility for resource management. SLURM controls the compute nodes, and intelligently schedules a vast array of highly heterogeneous calculations in order to maximize utilization (how much of the machine is active at one time), minimize wait times, and allocate the correct resources to each user. SLURM also accounts for the SUs consumed by each research group.
In this section, we will prepare and submit a SLURM job and learn how to choose the correct resources for future jobs.
A simple job
Recall the simple “Hello, World!” bash script from the previous section. In this section we will submit that job for use on a compute cluster. Create a new script using vi script.sh and add the following text. We include the sh prefix to indicate that this is a shell script, however this is not strictly necessary.
#!/bin/bash
#SBATCH -p express
#SBATCH -c 1
#SBATCH -t 0:5:0
set -e
echo "Hello, World!"
sleep 30
echo "Goodbye!"
date
Save and write the file. Each line has a special meaning.
- The first line is the hashbang we described earlier. Most SLURM jobs are bash scripts, however you can use other formats.
- The next three lines are
SBATCHdirectives. The preceeding hash character (#) marks them as comments, which means thatbashwill ignore them. SLURM will use them, however, to allocate resources. Syntax is very important: you cannot have any spaces until the end of the directive. - We have included the
set -ecommand which causes the script to exit on error. This is helpful later. If our script crashes, it will raise an error code in SLURM. Withoutset -e, it will simply move to the next line and appear to complete successfully. - The remainder of our script calls several programs, including the
echo,sleep, anddate, commands, which print to the terminal, wait for a while, and report the date, respectively.
SLURM flags
Each of the slurm flags above has a very specific meaning. You can use the short or long version of each flag, for example -p express is equivalent to --partition=express.
The partition
The -p or --partition flag specifies which “queue” or “partition” services the job. With only minor exceptions, these partitions represent distinct physical components on the machine. We have selected the express partition, which is also the default if you omit this flag. This is a high-availability partition with low resource limits to prevent a single user from dominating the hardware. It should have very little wait time, and helps users to keep their minor calculations and post-processing work off of the shared login nodes.
The number of cores
We have selected a single core -c 1 for this job. Many codes can use multiple cores or nodes. In the text below we will explain the best way to select the number of cores. For now we only need one.
The time limit
We do not expect that this script will take very long, hence we have selected 0 hours, 5 minutes, and 0 seconds i.e. 0:5:0. We always request slightly more time than necessary, otherwise SLURM will prematurely terminate our job.
Submitting the job
To execute this script, use the following command.
$ sbatch script.sh
Check the status of the job with squeue -u $USER or more simply, sqme. First the job will report a state (ST) that is pending (PD) and after a moment it will be running (R). About 30 seconds later it will be absent from the list. If you ls this directory, you will see an output file.
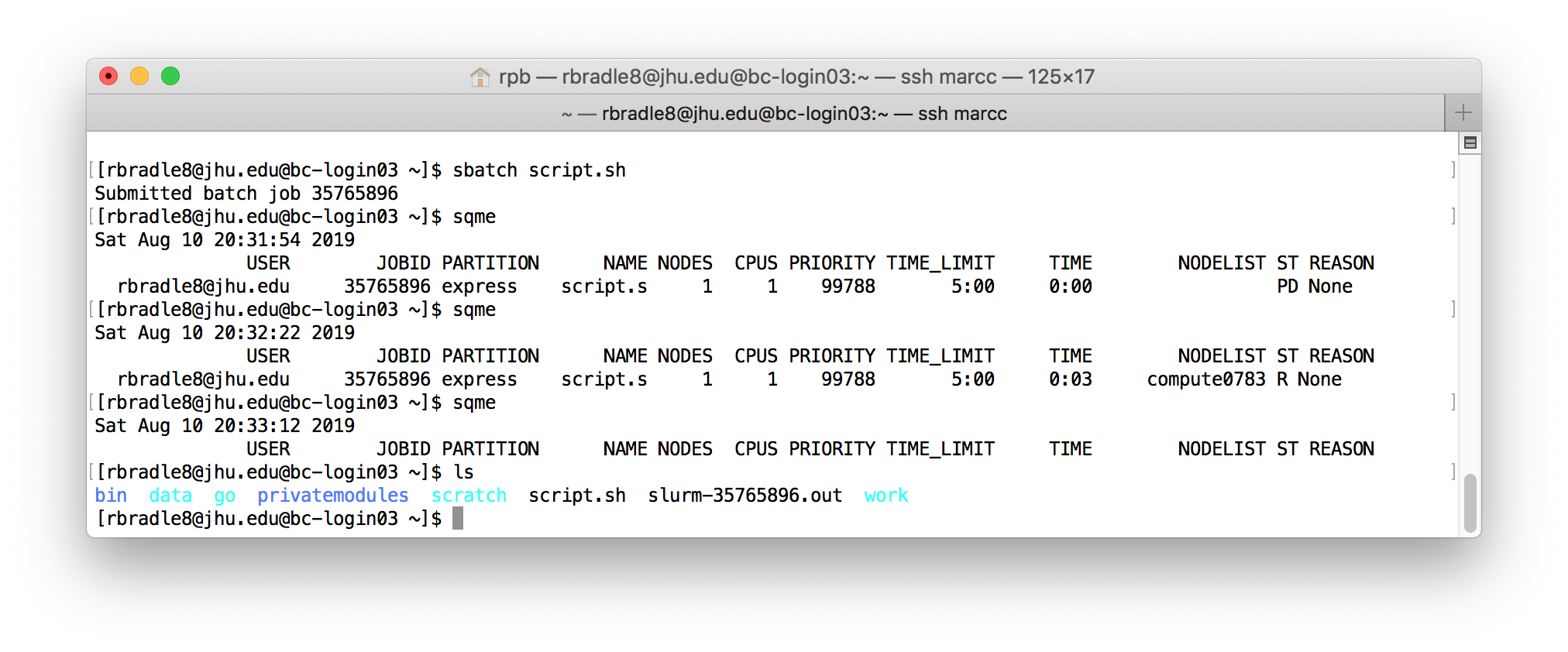
If you cat the log file, you can see the results of our calculation:
$ cat slurm-35765896.out
Hello, World!
Goodbye!
Sat Aug 10 20:32:58 EDT 2019
Note that the long number in the name of the log file, and in the squeue output above, is the SLURM job ID number, which uniquely identifies your job.
Blue Crab runs tens of thousands of jobs per day. Some are small, running on a single core, others may use up to 64 nodes at once.
In addition to submitting jobs with sbatch, you may also use scancel N to cancel job number N, sinfo to see the current status of all partitions, squeue -p <partition> to list all jobs for a particular partition, and sacct -u $USER to show completed jobs. Note that the variable $USER will be replaced with your username.
SLURM has many more features which are discussed at length on our website and in the documentation.
You may also add the following extra flags to your #SBATCH directives.
#SBATCH --mail-type=alland#SBATCH --mail-user=userid@jhu.edusends an email at the beginning and end of each job (or specify eitherbeginorendinstead ofall)#SBATCH --job-name=My-Job_Namesets a job name#SBATCH --account=[account]sets the account if you have multiple research groups associated with your username#SBATCH --nodes=1sets the number of nodes for a multi-node job, typically on theparallelpartition#SBATCH --ntasks-per-node=24sets the number of MPI tasks for each node, only for use with MPI-enabled codes
Choosing resources
The example above was easy. Choosing the right resource for your calculations may be significantly more difficult. To select the right resource for your calculation, you should answer the following questions.
- Is my calculation MPI-enabled?
- Is my calculation threaded or OpenMP-enabled? Can I make use of multiple cores at once?
- Does my calculation have any memory requirements?
- How long will my calculation take to complete?
- How well does my MPI or openMP code scale across resources?
- How many SUs do I have?
The answers to these questions will help determine which partition you should use. The partitions are summarized in the following table.
| Partition | Default/Max Time (hours) | Default/Max Cores per Node | Default/Max Memory per Node | Serial/Parallel | Backfilling | Limits |
|---|---|---|---|---|---|---|
| express (default) | 1 hr / 12 hrs | 1 / 6 | 3583 MB / ~86 GB | Serial (multi-thread) | Shared | 1 node per job |
| shared | 1 hr / 72 hrs | 1 / 24 | 4916 MB / ~117GB | Serial (multi-thread) | Shared | 1 node per job, 300 cores total |
| parallel | 1 hr / 72 hrs | 24 / 24 | 4196 MB / ~118 GB | Parallel | Exclusive | No limits |
| gpuk80 | 1 hr / 18 hrs | 1 / 24 | 4916 MB / ~118 GB CPU 20 GB GPU | Serial, Parallel | Shared | 4 GPUs / node |
| gpup100 | 1 hr / 12 hrs | 1 / 24 | 4916 MB / ~118 GB CPU 24 GB GPU | Serial | Shared | 2 GPUs (1 node) per user |
| lrgmem | 1 hr / 72 hrs | 1 / 48 | 120 GB / 1014 GB | Serial, Parallel | Shared | 5 nodes per job |
| scavenger | 6 hours | 1 / 24-28 | 4916 MB / ~118 GB | Serial, Parallel | Shared | 5 nodes per job |
| skylake | 1 hr / 72 hrs | 1 / 24 | 3583 MB / ~86 GB | Serial (multi-thread) | Shared | 1 node per job |
| unlimited | 1 hr / unlimited | 1 / 24 | 4916 GB / ~118 GB | Serial, parallel | Shared | not guaranteed to complete |
Compiling code
Do not use express or skylake to compile code. The newer architecture will add special features to your code which are not supported on the vast majority of the machine. Similarly, since our lrgmem partition has a slightly older architecture (Ivy Bridge), all code that must run on lrgmem should also be compiled there.
How to choose a partition
Here is a short guide to choosing a partition. Note that the nomenclature is somewhat overloaded: you can run a parallel or more accurately multi-threaded calculation on the shared partition. The shared partition can host exclusive jobs in which one user uses an entire node, but users may also request a portion of a node, thereby sharing it with other users.
The name of the parallel partition refers to the fact that most jobs use multiple nodes in parallel and therefore require MPI-enabled code and the use of the high-speed infiniband network. Note that a single-node, exclusive job is a rare point of intersection for both shared and parallel because this type of calculation is extremely common.
- Most jobs can run on the
shared,express, andskylakepartitions. - Do not request more than one core if your code does not include multi-threading or parallelism via OpenMP or MPI or a manually-compiled parallel toolkit. If you use MPI, you should use
mpiexecand if you useOpenMPi.e. threads, then you should set the BASH variable$OMP_NUM_THREADSto the right number of cores. - An exclusive, one-node, 24-core job can run on both
sharedandparallel. - If your job requires more than one node, and does not require excessive memory or a GPU, then you should use the
parallelpartition. - If your job requires more than one node, it must be an MPI-capable code. If you’re not sure if your code is MPI-capable, then it’s probably not. If you have an MPI-capable code, use
--ntasks-per-nodeinstead of--cpus-per-taskto request more cores. - If you require smore than
118GBmemory, you must use the large-memorylrgmempartitions. Otherwise, if your job requires up to117992MB, then you should request a single node onsharedorparallel. We will discuss memory usage in more detail below. - If your job requires only one GPU, then you should not request multiple GPUs. All requests for the GPU partitions should include the
gresflag (see below). Since theV100andP100GPUs are scarce, almost all GPU requests should be sent togpuk80.
MPI jobs
The name for an individual process in a message-processing interface (MPI) code is a “task”. MPI is required for all communication between nodes on our cluster.
Requesting GPUs
The gpuk80, gpup100, and gpuv100 partitions require that you request a certain number of GPUs for each node using the following directive. In the following example we will request 4 GPUs.
#SBATCH --gres=gpu:4
Do not request multiple GPUs unless you are absolutely certain that your calculation can use more than one GPU! Many GPU codes also use MPI, in which case you should almost always set the number of tasks per node equal to the number of GPUs per node that you are using, and only use threading to consume the extra cores via --cpus-per-task. Some codes alternately use the maximum number of MPI tasks (i.e. 1 for each processor on the node), set --cpus-per-task=1 and rely on the GPU code to correctly interact with the GPUs. This may be specific to each application.
Memory
You may have noticed that the memory limits above are awkward. This is by design. Our compute nodes are disk-less, which means that the operating system resides in memory. We allocate 10GB for the operating system.
More importantly, users should almost never need to make a special memory request with SLURM’s --mem flag. We ensure that we always allocate the maximum available memory for each core that you request. SLURM will charge your account for the number of SUs equivalent to your memory request, even if you use only a single core. If you request --mem=8GB and a single core, you will be charged instead for 2 cores, because each core has typically ~5GB of memory associated with it.
If you have a single-threaded calculation, then you should request memory with e.g. #SBATCH --mem=50GB. This will reserve about half of one node.
If you have a multi-threaded application, it is best to request cores to match your memory requirement so that you can also make use of the extra cores. Here is an example. Imagine that you have a multi-threaded code that can use many cores. You know that it requires between 20-25GB and you wish to optimize the number of SUs you spend. In that case, you should request 5 cores on shared because 5x4916 = 24580MB < 25GB. Some simple arithmetic can help you optimize your core count and SU consumption.
Overriding a slurm script
You can use the #SBATCH directives directly in the sbatch command to override the directives in your script. In this example, we are overriding the time limit.
sbatch --time=1:0:0 script.sh
You can also omit #SBATCH directives entirely and submit standard bash scripts to SLURM as long as you include all of the required flags in your sbatch call.
Benchmarking
Since MARCC offers its users only a finite amount of hours (SUs), and many codes are not guaranteed to perform twice as fast with twice as many nodes or cores, we strongly recommend that you benchmark your calculations to find the most efficient set of resources. The more efficient your calculation, the more calculations you can do with the same allocation.