Physical infrastructure
Our high performance computing (HPC) system, named Blue Crab is a supercomputer, formerly ranked in the top 500 worldwide. Capable of
~1.4 PFLOPS(a petaflop is one quadrillion floating-point operations per second), it is equivalent to~10,000laptop computers and consists of over23,000cores and over800nodes. The purpose of maintaining such a large computer is to perform computations at massive scale while also serving a very large community of academic researchers.
Terms
We use the following names to describe parts of the machine:
nodea single shelf in a rack. A node is equivalent to a single desktop computer.clustera network of nodes. Blue Crab is a cluster.processora single electronic circuit, also known as acore.memoryrandom access memory (RAM) including high bandwidth to thecore.diskstorage on a spinning disk separate from thenodeand comparatively slower thanmemory.
Compute hardware
Blue Crab has both compute and storage hardware. The compute hardware comes in three flavors:
780Standard compute nodes. These typically have 24 cores and128GBof memory.50Large memory nodes. These include 48 cores and1TBof memory.79Graphical processing unit (GPU) nodes. These typicaly have 24 cores,128GBof memory, and either 2 or 4 GPUs, in one of several types.
GPU hardware
We offer three kinds of GPUs, all from NVidia where NxM implies N compute nodes with M GPUs on each node.
Like all data centers and HPC resources, we use the Tesla line of NVidia products. These are distinct from the consumer line in three ways. First, they are more physically robust, which is a requirement for use in a dense, hot cluster. Second, they often have higher-bandwidth networking required to use many GPUs at once. Third, and most importantly, they include error-correcting code (ECC) memory which is necessary to prevent data corruption and enables binary-reproducible, double-precision calculations which are often necessary for physics-based calculations.
Storage
Blue Crab has two entirely independent file systems. These provide the usual “storage” which holds data on timescales up to months. Storage should not be confused with memory. The computer memory (i.e. RAM) is physically located on the compute nodes and disappears at the end of your calculation. Memory can swallow a deluge of data coming from a processor. Storage that exists on the disks that comprise even our best-performing filesystem has a much lower bandwidth than the on-board memory.
Lustre storage: the “scratch” system
The fastest storage is provided by a 2PB (two petabyte, or 2000 terabtyes) Lustre system which is connected via Infiniband (IB) to all compute nodes. We call this the “scratch” system because it is meant to be used in a manner similar to memory, that is, as temporary storage with a maximum lifespan of six months, and is designed to enable high-speed I/O operations. Lustre is not optimal for hosting many tiny files, compiling code, or serving programs (binaries) to your calculations. The ~/scratch and ~/work folders (the latter is shared within research groups) occupy the Lustre system.
ZFS storage
Home directories at the ~/ and ~/data folders are hosted on the much larger 12PB ZFS storage system is designed for longer-term but still non-permanent storage. It is suitable for hosting shared data sets and both inputs and outputs from your calculations.
Physical plant
The components listed above occupy a single physical plant pictured below. Our site has room for five machines, however only one has been built so far.

The machine sits on a concrete palette, including large cooling facilities and a flywheel which supplies power in the event of an outage.

Network topology
A more informative map of the system includes the high-speed network, storage components, compute nodes, and access to the public via the internet.
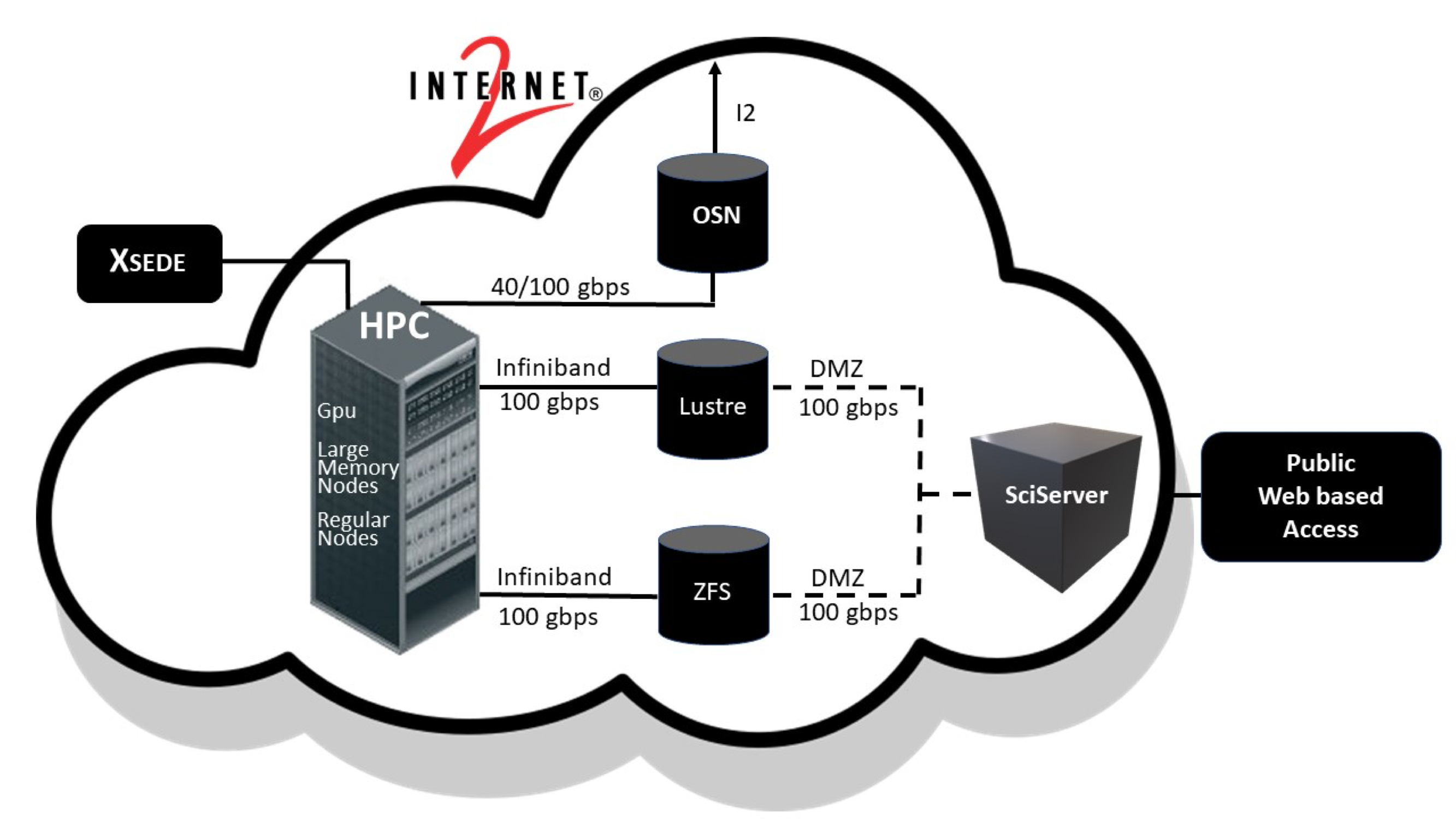
The figure above includes connections to the national NSF-funded computational infrastructure called XSEDE, the open-storage network (OSN), and SciServer, which connections are forthcoming.
Not pictured are the “login nodes” which are the primary gateway to the HPC resource.
Login nodes and the scheduler
All shared HPC resources use login nodes sometimes called the “head node” to host users who otherwise cannot access the compute hardware directly. Users log on to the head node from which they can access storage, perform minor bookkeeping tasks – for example, writing a script – and then send instructions to the scheduler. The scheduler allocates resources. Our scheduler is called SLURM and will be described at length.
Shared HPC resources are called “multi-tenant” because many people use them at once. Since we cannot build perfect safeguards to prevent users from interfering with others or damaging the machine, all users are collectively responsible for using the machine carefully. In practice this means that you cannot run calculations on the shared login nodes and you must thoughtfully schedule your jobs on the appropriate hardware. We will explain how to do this in the coming sections.